主页 > imtoken官网下载2.0苹果 > 以太坊 6 挖矿算法
以太坊 6 挖矿算法
6.挖矿算法6.1 scrypt算法
PoW本身是为了让记账权随机分配给每个节点而产生的,但是现在有人用专用的ASIC芯片,而且迭代速度很快,挖矿作为一个职业已经普及,这已经违背了PoW 的初衷。中本聪将比特币作为一种去中心化的加密货币,可以理解为电子黄金的投资或保值产品。因此,需要使用一种抗ASIC的算法,即抗ASIC。如果对计算速度的要求降低,对内存的要求必然会提高,也就是内存硬挖难题。莱特币使用 scrypt 算法。
有一个数组x,先用一个伪随机数种子找到hash放到x[0]中,然后找到x[i+1]=HASH(x[i]),直到整个数组被填满,这个数组是一个要查找的表。在实际使用中,先找到A,再通过哈希A找到B,再通过哈希B找到C,直到最终找到结果。如果不使用这个表,需要从数组头计算B的值,而当使用C通过数组头查找时asic芯片挖矿,效率会很低,所以时间的问题是转化为空间问题。

开头的数字必须是伪随机数。肖先生说以后查不到了。
有些矿工只存储奇数仓位的值,偶数仓位可以用奇数仓位一步计算。
scrypt 算法的缺点是空间。轻节点在验证时也需要维护这个数组。如果是电脑维护一个1G的阵列,还是挺简单的,但是如果是手机,开销可能会很大。但是,莱特币本身并没有轻全节点的区别。
6.2以太坊挖矿算法ethash原理
以太坊中有两个数组,一个是缓存,另一个是数据集(也称为 DAG)。有16M,数据集有1G。轻节点只维护缓存,全节点维护两者。两个数组每增加30000块,增加原来的1/128,是原来的128分之一,因为内存技术也在逐渐增加。
使用时,先用一个伪随机种子种子按顺序生成这个数组,第0个数字是种子的哈希值,第一个数字是第0个数字的哈希值,依此类推。生成缓存的过程比较繁琐。它遍历每个数据集的位置,用一个方法在缓存中找到对应的下标(这个方法是用数据集的下标取缓存中元素个数的余数然后异或,不知道为什么XOR写在下面),当然是找到对应的hash值了,假设是A。然后用A找B,再找Casic芯片挖矿,连续执行256次,得到数据集中的这个元素。
如何使用这个数据集?用一种特殊的方式遍历数据集(这个方法我就不写了,代码在里面),遍历的时候生成一个hash,最后遍历整个数据集。得到的hash就是结果,就是在挖矿的时候验证目标。啊,或者其他节点的验证结果,就可以了。
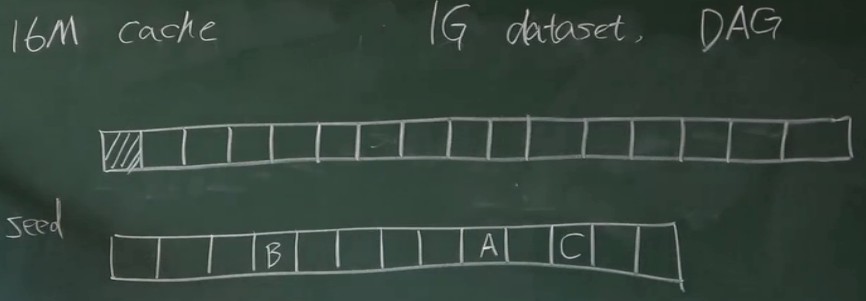
6.3 以太坊挖矿算法ethash源码
以下函数用于根据种子代码生成伪缓存。每 30,000 个块重新生成一个新种子(新种子是原始种子的哈希值),并基于新种子生成新的缓存。缓存的初始大小为16M,每30000块增加初始大小的1/128,即128K。每个节点的hash值是前一个节点hash的结果,cache_size是缓存数组的大小,seed是伪随机数种子。
def mkcache(cache_size, seed):
o = [hash(seed)]
for i in range(1, cache_size):
o.append(hash(o[-1]))
return o
以下函数用于根据缓存遍历full_size生成数据集。 full_size 自然是数据集的数组大小,cache 就是缓存数组。这个数据集叫做DAG,初始大小为1G,每30000块更新一次,同时增加初始大小的1/128,即8M。
def calc_dataset(full_size, cache):
return [calc_dataset_item(cache,i) for i in range(full_size)]
下面的函数用来遍历数据集的每一位生成数据集,缓存就是整个缓存数组。 (这句话是我抄的)首先通过缓存中的i%cache_size元素生成初始混合,因为两个不同的数据集元素可能对应同一个缓存中的元素,为了保证每个初始混合不同,请注意,我也参与了哈希计算。 get_int_from_item() 函数的作用是从当前哈希值中找到下一个要读取的位置。 make_item() 使用前一个缓存索引和哈希值来查找下一个哈希值。缓存中的数据经过256次hash,返回结果,可以存储到dataset中。
def calc_dataset_item(cache, i):
cache_size = cache.size
mix = hash(cache[i % cache_size] ^ i)
for j in rage(256):
cache_index = get_int_from_item(mix)
mix = make_item(mix, cache[cache_index % cache_size])
return hash(mix)
下面第一个是全节点,第二个是轻节点,返回hash值。全节点和轻节点的区别在于轻节点不存储数据集,每个值都是现在获取的。轻节点用于验证nonce是否有效,全节点用于对nonce进行一一尝试。 header 是当前要生成的块的块头,nonce 是尝试次数,full_size 是数据集的大小,这个值每 30000 个块改变一次,1G 的 1/128 增加 8M。以太坊和比特币一样,仅使用区块头信息进行挖掘,因为这允许轻节点仅使用区块头进行验证。当我查看代码时,我遇到了问题。 for循环中mix的值是不断修改的,返回的只能是最后一个结果。两次执行 make_item() 有什么意义?第5行的mix也是第6行的参数,简单来说就是按照预定的方式遍历数据集,直到得到最终的hash结果。
def hashimoto_full(header, nonce, full_size, dataset)
mix = hash(header, nonce)
for i in range(64):
dataset_index = get_int_from_item(mix) % full_size
mix = make_item(mix, dataset[dataset_index])
mix = make_item(mix, dataset[dataset_index + 1])
return hash(mix)
def hashimoto_light(header, nonce, full_size, cache)
mix = hash(header, nonce)
for i in range(64):
dataset_index = get_int_from_item(mix) % full_size
mix = make_item(mix, calc_dataset_item(cache,dataset[dataset_index]))
mix = make_item(mix, calc_dataset_item(cache,dataset[dataset_index + 1]))
return hash(mix)
下面的函数用于挖掘找到满足目标的节点。具体内容就不用说了。
def mine(full_size, dataset, header, target):
nonce = random.randint(0,2**64)
while hashimoto_full(header, nonce, full_size, dataset) > target
nonce = (nonce + 1) % 2**64
return nonce
6.4 ASIC 电阻
为了实现抗ASIC,以太坊打算将PoW转换为PoS,也就是将工作量转换为PoS,但是都没有变现,变现的时间也被推后了。因为ASIC芯片的研发周期在一年左右,以太坊一直在吓唬矿机厂商:我们要证明权益,搞它的矿机厂商不敢大规模生产。事实证明非常有效。以太坊的 ASIC 芯片不多,也没有比特币那么泛滥。也可能与ethash有关。
我们应该设计抵抗 ASIC 芯片的算法吗?抵抗后,更多的通用设备可以参与挖矿。以太坊和莱特币就是这样做的。积极的态度是因为参与挖矿的普通设备越多,参与挖矿的人越多,挖矿的结果越民主,区块链越安全。负面认为ASIC芯片大大增加了挖矿成本。首先,ASIC芯片的研发周期在1年左右,芯片称霸的时间也很短,而且ASIC芯片是专门为某种货币挖矿而设计的。尚不可用于另一枚硬币。如果有人需要发起攻击,需要大量购买ASIC矿机,很可能攻击后币价会暴跌,完全吃力不讨好。如果很多通用设备都可以参与挖矿,那么亚马逊、阿里云等拥有超强云计算能力的公司可能在全球拥有足够的服务器来攻击币。虽然这笔钱对那些公司来说可能不算多,但如果他们觉得以太坊的一些记录或数据威胁到自己,可以集中算力干掉以太坊,服务器会继续租用,大幅减少 51% 的成本。